
# What is Mira?
To see a star that varies intrinsically in brightness, we have to wait until late summer and fall. Mira, in the constellation Cetus the Whale, is the sky’s best slowly varying red giant. Mira climbs from invisibility (at 9th magnitude) to 4th magnitude and then fades again roughly every 330 days. —Alister Ling, Astronomy, January 1992
The star that we see when look at Mira is a variable red giant, the brightest of a binary pair of variable stars, and was one of the first variable stars identified by astronomers.
1997 年拍下的米拉星

1. Background Story
Far memory 是常见需求:
- 提升内存资源的利用率
- 降低内存使用的成本(慢但是便宜的内存构成远程内存池)
- 满足大内存的需求
现有方案
PlanA: swap page
Infiniswap、Fastswap- 优点:transparent(应用直接用,不用改)
- 缺点:
- 存在 IO 放大问题,例如应用以对象粒度的访问导致缺页后 OS 会将整个 4 KB 页读回
- 无法结合应用程序语义进行进一步优化
PlanB:New programming models
FaRM、AIFM- 优点:没有 IO 放大的问题
- 缺点:
- 要改应用
- 可能引入额外的运行时开销(比如 AIFM 需要引入一个运行时来执行 remote pointer 的解引用)
2. Insight
「使用程序分析和编译器来协助远程内存访问」这条路存在潜力
举个例子 🌰:
for (int i = 0; i < size; i++)
B[A[i]]++;用编译器在操作之前插入 prefetch:
%1=(fetch A[i+distance])
fetch B[%1] at distanceLocal-Far memory 具有软件定义 cache 的特性
- Cache-DRAM 的结构已经被研究很多了
- 但 local-far memory 的结构是基于 DRAM 的,软件定义一切
- 作为 cache 的 local memory 是可以变的
一个程序往往会在不同对象或不同阶段表现出几种不同的内存访问模式
- 举个例子:
- 对于顺序访问,直接映射、cache 大小为多个连续元素的配置效果好
- 对于有比较好的 locality,但 working set 比较大的任务,则适合大缓存、组相联
- 使用定制化的 cache 配置能够提升程序的性能
- Mira 把 local cache 切分成 space 供不同的访问模式的代码使用
- 并利用编译器根据静态和动态分析的结果,调整一系列的 cache 参数:
- Cache section 的大小
- Cache structure(set-/full-associative)
- Cache line 的大小
- Prefetching 和 eviction pattern
- Communication method(one-/two-sided RDMA)
3. Design
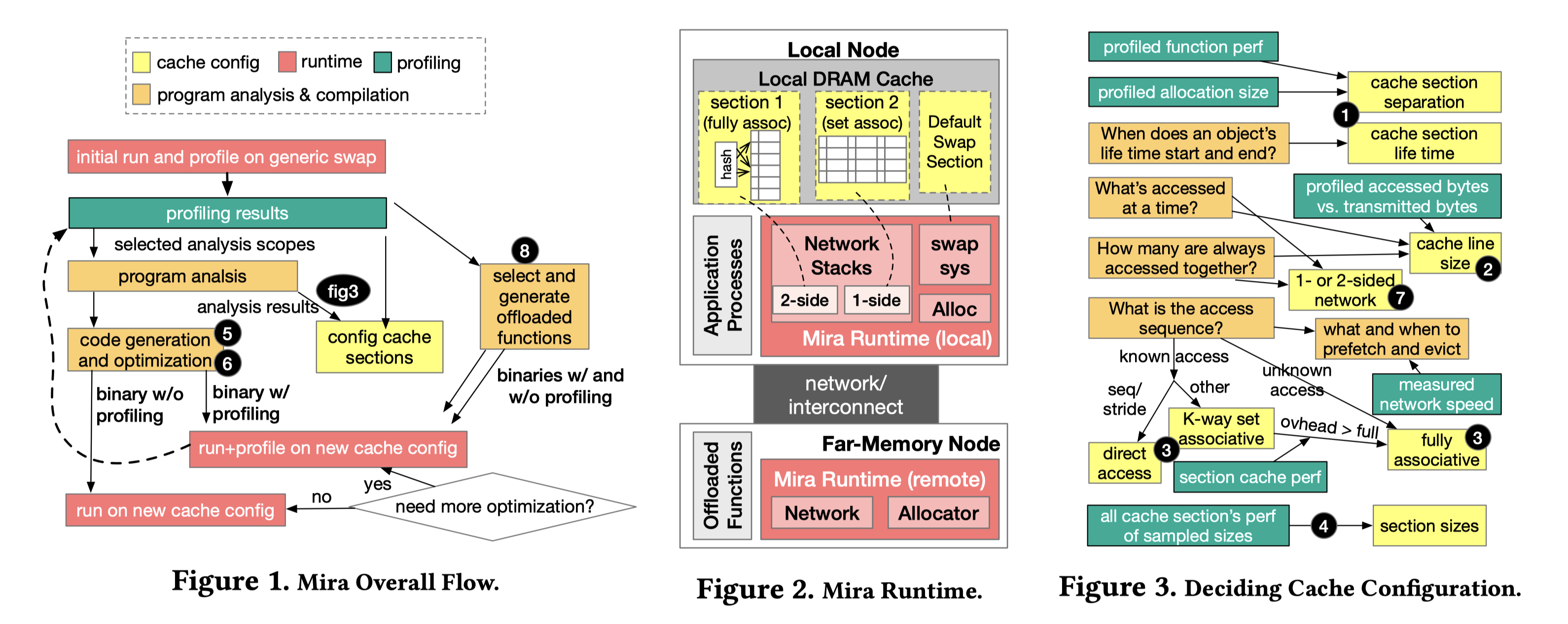
- Mira 包含:
- 程序分析工具
- 编译器
- Local-node runtime
- Remote-node runtime
- Profiling system
Overall Flow
- 用 swap 系统做 profiling,把所有的堆变量和静态变量都放在 swap 系统上
- 收集 profiling 数据,包括每个函数的 miss rate、miss latency、hit overhead 以及执行时间,最后还有每个对象的大小
- 根据结果来:
- 分割 cache sections
- 决定 cache configuration
- 根据生命周期:
- 何时开始和结束 cache section
- 根据数据访问的大小:
- Cache line 的大小
- 根据内存的访问顺序和分析的 cache section 的性能
- Cache 的结构
- 根据全局的信息来决定 cache section 的大小
- 根据生命周期:
- 代码生成
- 把内存操作都转化成对 mira runtime 的访问,再根据情况转化成 cache 或网络访问
- 根据应用的特点选择合适的网络栈(one-/two-sided RDMA)
- 代码优化
- Adaptive prefetching:区别于传统的基于运行时的访问历史进行数据预取,Mira 使用程序分析来判断未来会被访问到的对象。比如程序在多级循环中中进行内存访问,Mira 根据循环模式进行 prefetch。Mira 使用编译器在程序中插入异步的预取操作。
- Eviction hints:Mira 在访问一个对象时,lock 住对应的 cache,在结束后主动发起一次异步的 cache flush 操作
- Selective transmission:如果程序访问对象时只访问其中某些字段,那么从远端内存读取整个对象会造成 IO 放大问题。面对此类情况,Mira 仅读取对象中会被访问的字段
- 过程可以持续多次,进一步优化性能 (设置一个优化的目标,e.g. 最多十轮 or 一直优化直到相比上一轮没有更多提升)
- 最后,mira 还会考虑每个函数的计算量以及网络的流量,将特定的函数 offload 到有计算能力的 far memory 节点上
4. Evaluation
Evaluation Environment
- Cloudlab cluster of eight
c6220servers, each equipped with:- two 8-core Intel Xeon
E5-2560CPUs (2.6 GHz),- 64 GB RAM,
- 50 Gbps Mellanox FDRCX 3 NIC with 50 Gbps Infiniband network.
Applications
- DataFrame
- MCF
- GPT-2 inference
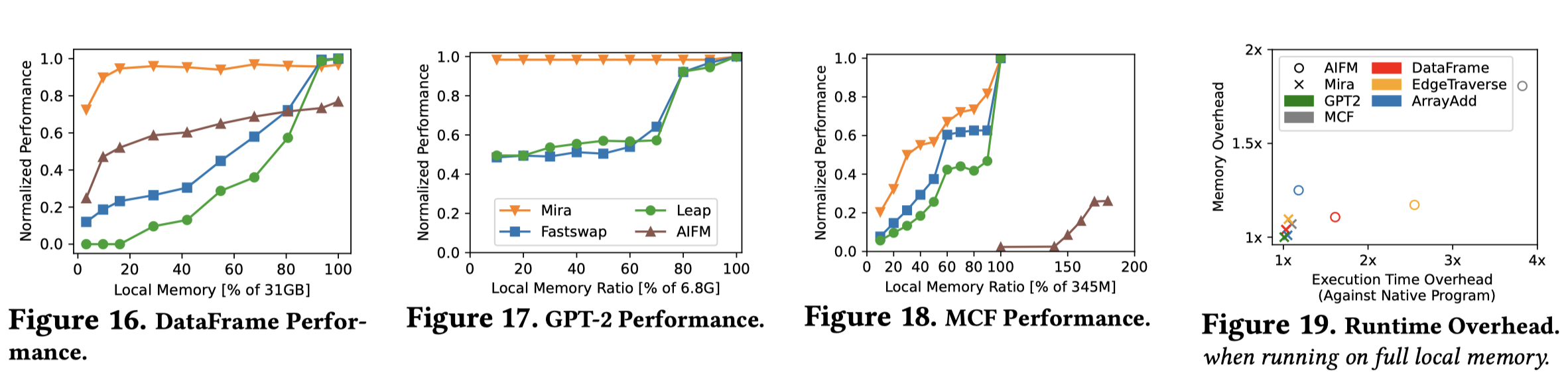
- 相对性能,基准是纯 local-cache 的性能
- Mira 和 AIFM 的粒度更细,相对性能更优
- Mira 没有 AIFM 的 runtime 带来的解引用开销
- 在 GPT-2 中,Mira 的性能几乎没有随 local memory 大小减小而下降。主要是因为 DNN 中每一个 layer 用到的数据之后都不会再被使用,所以 Mira 可以把不同 layer 用到的矩阵放置在不同的 cache 分区中,并进行高效的 eviction 和 prefetch,带来的好处就是在关键路径上的几乎所有访问都是本地的。
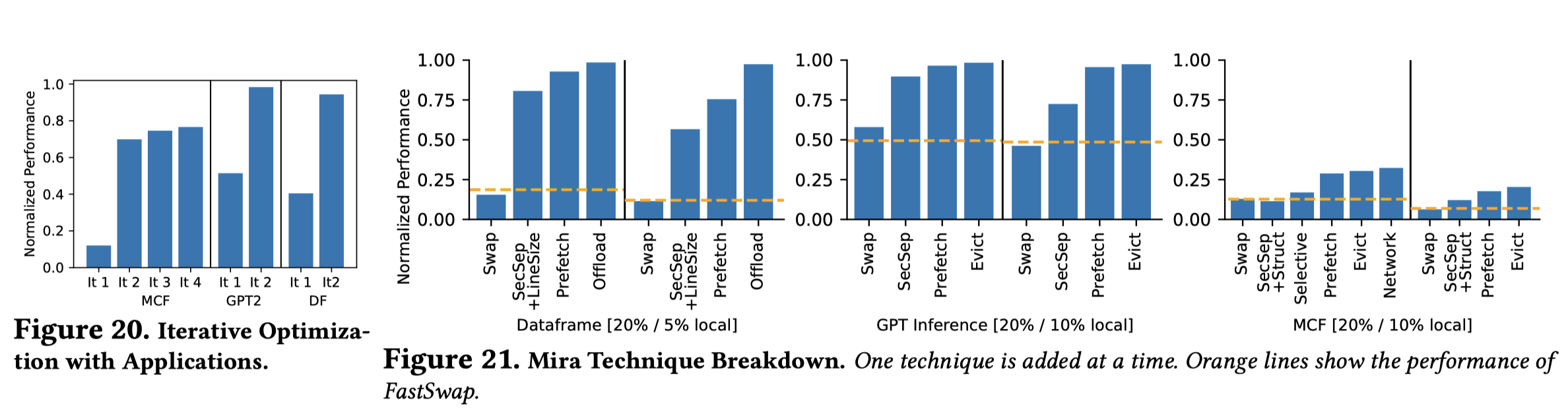
- Mira 还对其每个优化技术带来的性能提升做了 breakdown 分析,可以看出将应用的 local cache 进行合理分区可以带来最显著的性能提升。
Footnotes
-
Saba Jamilan, Tanvir Ahmed Khan, Grant Ayers, Baris Kasikci, and Heiner Litz. 2022. Apt-get: Profile-guided timely software prefetching. In Proceedings of the Seventeenth European Conference on Computer Systems (EuroSys ’22). Rennes, France. ↩
-
Maksim Panchenko, Rafael Auler, Bill Nell, and Guilherme Ottoni. 2019. Bolt: a practical binary optimizer for data centers and beyond. In 2019 IEEE/ACM International Symposium on Code Generation and Optimization (CGO ’19). Washington DC. ↩